1. 머신러닝(Machine Learning)
- 인공지능: 인공(Artificial) + 지능(Intelligence)
- 1956: 인간의 지능을 복제하거나 능가할 수 있는 지능형 기계를 만들고자 하는 컴퓨터 과학분야
- 개발자에 의한 인공지능, 데이터에 의한 인공지능
- 머신러닝: 데이터를 기반으로 한 학습(Learning)하는 기계(machine)
- 1977: 기계가 기존 데이터에서 학습하고 해당 데이터를 개선하여 의사 결정 또는 예측을 할 수 있도록 하는 AI의 하위 집합
- 딥러닝: 깊은(deep) 신경망 구조의 머신러닝
- 2017: 신경망 레이어를 사용하여 데이터를 처리하고 결정을 내리는 기계 학습 기술
- Generative AI
- 2021: 프롬프트나 기존 데이터를 기반으로 새로운 문서, 시각, 청각, 컨텐츠를 생성하는 기술
- ChatGPT
- 2022: GPT(Generative Pre-trained Transformer) 시리즈를 기반으로 하는 OpenAI가 개발한 대화형 AI모델

2. 머신러닝의 정의
- 배경: 데이터를 대량으로 수집 처리할 수 있는 환경이 갖춰짐으로 머신러닝으로 할 수 있는 일들이 많아짐
- 머신러닝은 데이터로부터 특징이나 패턴을 찾아내는 것이기 때문에 데이터가 가장 중요함
- 인공지능의 한 분야로 컴퓨터가 학습할 수 있도록 알고리즘과 기술을 개발하는 분야
- "무엇(x)으로 무엇(y)을 예측하고 싶다"의 f(함수)를 찾아내는 것
- x: 입력변수(독립변수), y: 출력변수(종속변수), f모형(머신러닝 알고리즘)
3. 머신러닝으로 할 수 있는 것
3-1. 회귀(Regression)
- 시계열(시간적인 변화를 연속적으로 관측한 데이터) 데이터 같은 연속된 데이터를 취급할 때 사용하는 기법
- 예측
- 예) 과거 주식 추세를 학습해서 내일의 주가를 예측하는 시스템을 개발
3-2. 분류(Classification)
- 주어진 데이터를 클래스별로 구별해 내는 과정으로 데이터와 데이터의 레이블값을 학습시키고 어느 범주에 속한 데이터인지 판단
- 예) 스팸메일인지 아닌지 구별해주는 시스템을 개발
3-3. 클러스터링(Clustering)
- 분류와 비슷하지만 데이터에 레이블이없음
- 유사한 속성들을 갖는 데이터를 일정한 수의 군집으로 그룹핑하는 비지도 학습
- 예) SNS 데이터를 통해 소셜 및 사회 이슈를 파악
4. 학습
4-1. 지도 학습(Supercised Learning)
- 문제와 정답을 모두 학습시켜 예측 또는 분류하는 문제
- y=f(x)에 대하여 입력 변수(x)와 출력 변수(y)의 관계에 대하여 모델링 하는 것
- y에 대하여 예측 또는 분류하는 문제
4-2. 비지도 학습(Unsupervised Learning)
- 출력 변수(y)가 존재하지 않고, 입력 변수(x) 간의 관계에 대해 모델링 하는 것
- 군집분석: 유사한 데이터끼리 그룹화
- PCA: 독립변수들의 차원을 축소화
4-3. 자기지도 학습(Self-Supercised Learning)
- 데이터 자체에서 스스로 레이블을 생성하여 학습에 이용하는 방법
- 다량의 Label이 없는 Raw Data로 부터 데이터 부분들의 관계를 통해 Label을 자동으로 생성하여 지도 학습에 이용하는 비지도 학습 기법
- GPT, BERT 모델
4-4. 강화학습(Reinforcement Learning)
- 결정을 순차적으로 내려야 하는 문제에 적용
- 레이블이 있는 데이터를 통해서 가중치와 편향을 학습하는 것과 비슷하게 보상이라는 개념을 사용하여 가중치와 편향을 학습하는 것
1. 사이킷런(Scikit-learn)
- 대표적인 파이썬 머신러닝 모듈
- 다양한 머신러닝 알고리즘을 제공
- 다양한 샘플 데이터를 제공
- 머신러닝 결과를 검증하는 기능을 제공
- BSD 라이선스이기 때문에 무료로 사용 및 배포가 가능
- [사이킷런 공식 홈페이지](https://scikit-learn.org/)
2. LinearSVC
- 클래스를 구분으로 하는 분류 문제에서 각 클래스를 잘 구분하는 선을 그려주는 방식을 사용하는 알고리즘
- 지도학습 알고리즘을 사용하는 학습 전용 데이터와 결과 전용 데이터를 모두 가지고 있어야 사용이 가능
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
# 학습 데이터를 준비
learn_data = [[0, 0], [1, 0], [0, 1], [1, 1]] # 독립변수
learn_label = [0, 0, 0, 1] # 종속변수
# 모델 객체 생성
svc = LinearSVC()
# 학습
svc.fit(learn_data, learn_label)# 검증 데이터 준비
test_data = [[0, 0], [1, 0], [0, 1], [1, 1]]
# 예측
test_label = svc.predict(test_data)
test_label# 결과 검증
print(test_data, '의 예측 결과', test_label)
print('정답률:', accuracy_score([0, 0, 0, 1], test_label))
3. 아이리스 데이터셋
- 데이터셋: 특정한 작업을 위해 데이터를 관련성 있게 모아 놓은 것
- [사이킷런 데이터셋 페이지](https://scikit-learn.org/stable/api/sklearn.datasets.html#module-sklearn.datasets)
sklearn.datasets
Utilities to load popular datasets and artificial data generators. User guide. See the Dataset loading utilities section for further details. Loaders: Sample generators:
scikit-learn.org
from sklearn.datasets import load_iris
iris = load_iris()
irisprint(iris.DESCR)

data = iris['data']
data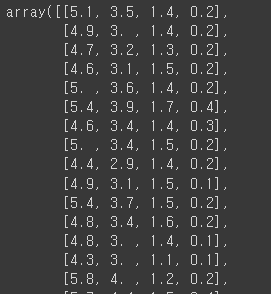
feature_names = iris['feature_names']
feature_names
import pandas as pd
df_iris = pd.DataFrame(data, columns=feature_names)
df_iris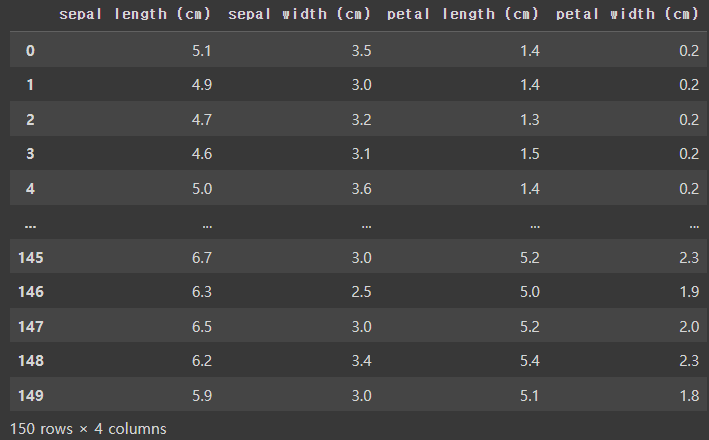
target = iris['target']
target
target.shape
df_iris['target'] = target
df_iris
from sklearn.model_selection import train_test_split# train_test_split(독립변수, 종속변수, 테스트사이즈, 시드값 ...)
X_train, X_test, y_train, y_test = train_test_split(df_iris.drop('target', axis=1),
df_iris['target'],
test_size=0.2,
random_state=2023)X_train.shape, X_test.shape
y_train.shape, y_test.shape
X_train
y_train
from sklearn.svm import SVC
from sklearn.metrics import accuracy_scoresvc = SVC()svc.fit(X_train, y_train)
y_pred = svc.predict(X_test)
y_pred
print('정답률', accuracy_score(y_test, y_pred))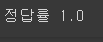
# 6.2 2.1 4.1 1.5
y_pred = svc.predict([[6.2, 2.1, 4.1, 1.5]])
y_pred
4. 타이타닉 데이터셋
1. 캐글(Kaggle)
- 구글에서 운영하는 전세계 AI개발자, 데이터 사이언티스트들이 데이터를 분석하고 토론할 수 있는 자료 등을 제공
- 데이터 분석 및 머신러닝, 딥러닝 대회를 개최
- 데이터셋, 파이썬 자료, R 자료 등을 제공
- [캐글 공식](https:/https://kaggle.com/)
2. 데이콘(Dacon)
- 국내 최초 AI 해커톤 플랫폼
- 전문 인력 채용과 학습을 할 수 있는 여러가지 AI자료 등을 제공
- [데이콘](https:/https://dacon.io//)
3. AI허브
- 한국지능정보사회진흥원이 운영하는 AI 통합 플랫폼
- AI 기술 및 제품 서비스 개발에 필요한 AI 인프라를 제공
- [AI 허브](/https:/http://www.aihub.or.kr/)
4. 타이터닉 데이터
import pandas as pddf = pd.read_csv('https://bit.ly/fc-ml-titanic')
df
5. 데이터 전처리
- 데이터 정제 작업을 뜻함
- 필요없는 데이터를 삭제하고, null이 있는 행을 처리하고, 정규화/표준화 등의 많은 작업들을 포함
- 머신러닝, 딥러닝 실무에서 전처리가 차지하는 중요도는 50% 이상이라고 봄
5-1. 독립변수와 종속변수 나누기
# feature = ['Pclass', 'Sex', 'Age', 'Fare'] # 독립변수
# label = ['Survived'] # 종속변수
columns = ['Pclass', 'Sex', 'Age', 'Fare', 'Survived']df[columns].head()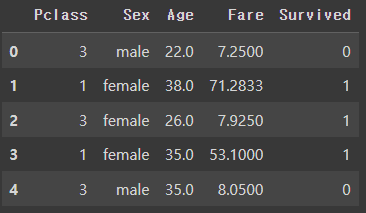
df['Survived'].head()
df['Survived'].value_counts()
5-2. 결측치 처리
df.info()
df.isnull().sum()
df.isnull().mean()
df['Age'] = df['Age'].fillna(df['Age'].mean())
df['Age']
5-3. 라벨 인코딩(Label Encoding)
- 문자(Categorical)를 수치(Numerical)로 변환
df.info()
df['Sex'].value_counts()
# 남자는 1, 여자는 0으로 변환하는 함수
def convert_sex(data):
if data == 'male':
return 1
elif data == 'female':
return 0df['Sex'] = df['Sex'].apply(convert_sex)
df.head()
from sklearn.preprocessing import LabelEncoderle = LabelEncoder()df['Embarked'].value_counts() # null은 제거
embarked = le.fit_transform(df['Embarked'])
embarked # null: 3
le.classes_ # array(['C', 'Q', 'S', nan]
5-4. 원 핫 인코딩(One Hot Encoding)
- 독립적인 데이터는 별도의 컬럼으로 분리하고 각각 컬럼에 해당 값에만 1, 나머지는 0의 값을 갖게 하는 방법
df['Embarked_num'] = LabelEncoder().fit_transform(df['Embarked'])
df.head()
pd.get_dummies(df['Embarked_num'])
df = pd.get_dummies(df, columns=['Embarked'])
df.head()
df = df[columns]
df
df = pd.get_dummies(df, columns=['Pclass', 'Sex'])
df.head()
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(df.drop('Survived', axis=1), df['Survived'], test_size=0.2, random_state=2024)X_train.shape, X_test.shape
y_train.shape, y_test.shape
X_train



